Engineering teams
Review the exact screen, selector, quote, and severity before deciding what should be fixed.
Point Flock at a public, preview, or staging URL. A persona tries a real goal, then Flock returns ranked findings with screenshots, page text, DOM or console evidence, and a scoped fix brief before launch or broader rollout.
Who it's for
Flock turns product review into an every-run check. Test the same critical flows against real user goals, capture the evidence, and move product QA into the release path.
Review the exact screen, selector, quote, and severity before deciding what should be fixed.
See where users lose confidence without replacing product judgment with a generic score.
Add user-facing regression signal before launch, before merge, or after risky workflow changes.
Example persona panel
Novice user
Can I complete the first task without support?
Busy operator
Can I get to the next step quickly?
Security admin
Can I trust what this workflow is asking me to do?
Skeptical evaluator
Is there enough evidence to keep evaluating?
Example review
Inspect what the persona saw, where the flow broke down, and what should change before release.
Review summary
Review dashboard
Synthetic UX review batch
Runs
4
Completed review runs
Findings
12
Ranked by severity
Abandonment
0%
Observed across panel
Evidence
Synthetic user review
Synthetic users find UX friction
The review keeps the screen and finding together.
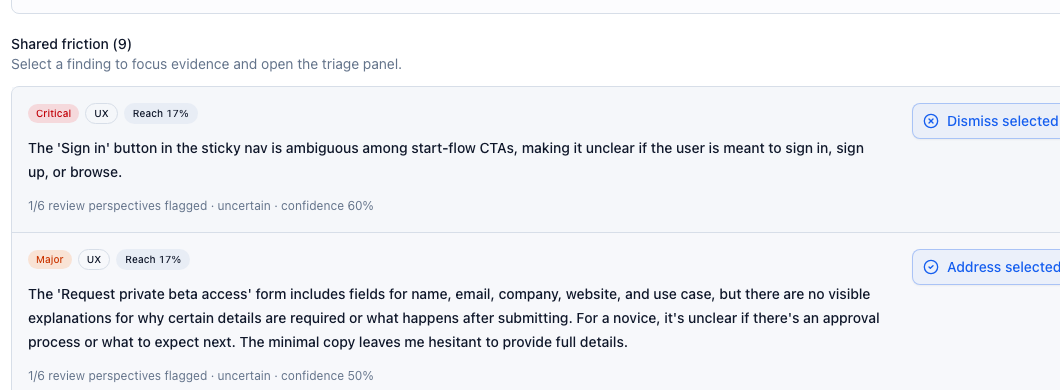
Friction events
"The access path is visible, but the next step is ambiguous."
a[href="/?modal=waitlist"]
"The review result is useful, but needs context near the decision point."
article[aria-label="review"]
Consensus
Consensus impression
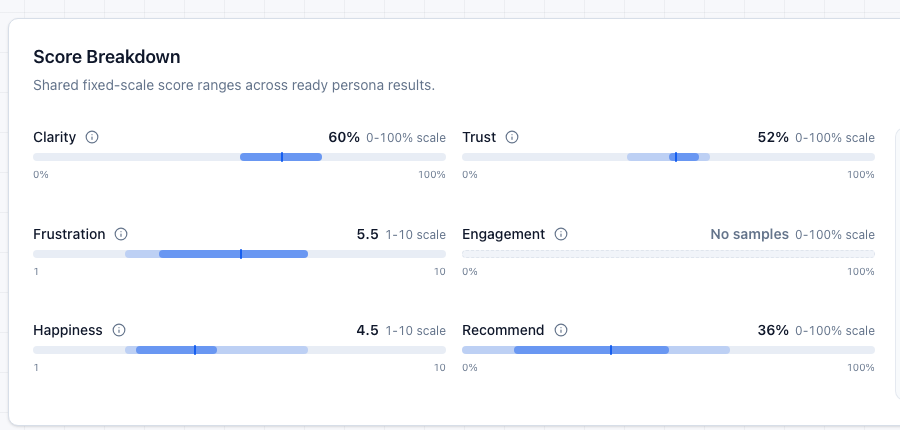
Personas converged on the same decision-point issue.
Clarity
75%
Trust
70%
Frustration
3.3 / 10
Timeline
Session timeline
Persona-level narration attached to the replay.
00:00
Session started
00:22
Scanned hero and request access
00:43
Major friction logged
00:58
Session ended
Fix brief
Fix brief
Accepted findings become scoped implementation notes.
# Fix selected review finding
- Fix the stale shipping summary after ZIP changes.
- Preserve the selected shipping method.
- Rerun the same persona goal before release.
Internal private-beta review
The useful findings were practical: a checkout path sent users into public pricing, a plan gate disagreed with billing state, and a workspace flow ended without a clear next step.
These examples come from one internal private-beta review. They are internal product evidence, not customer claims or an audited benchmark. Read the founder note.
Workspace setup
01Checkout path
02Plan state
03Workspace copy
04Pricing copy
05Review context
06Public walkthrough
After using the loop internally, we made it inspectable on a familiar public page family: three archived Amazon homepages, one shopper goal, and visible screens that make the findings legible.
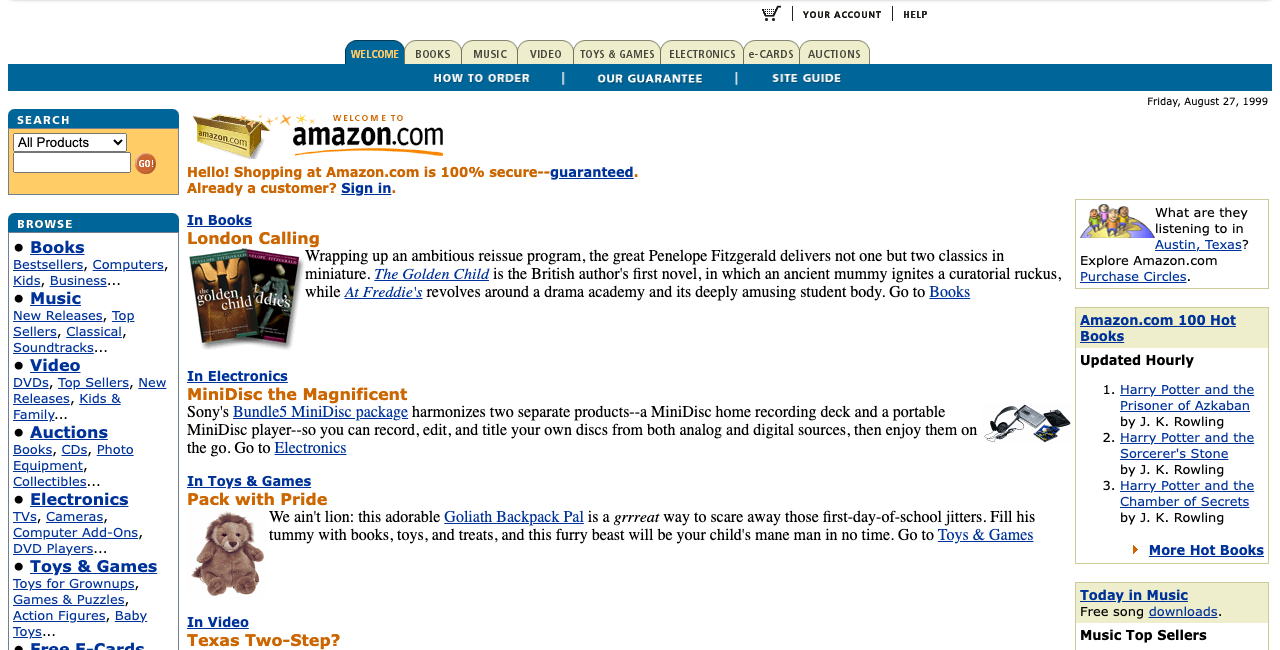
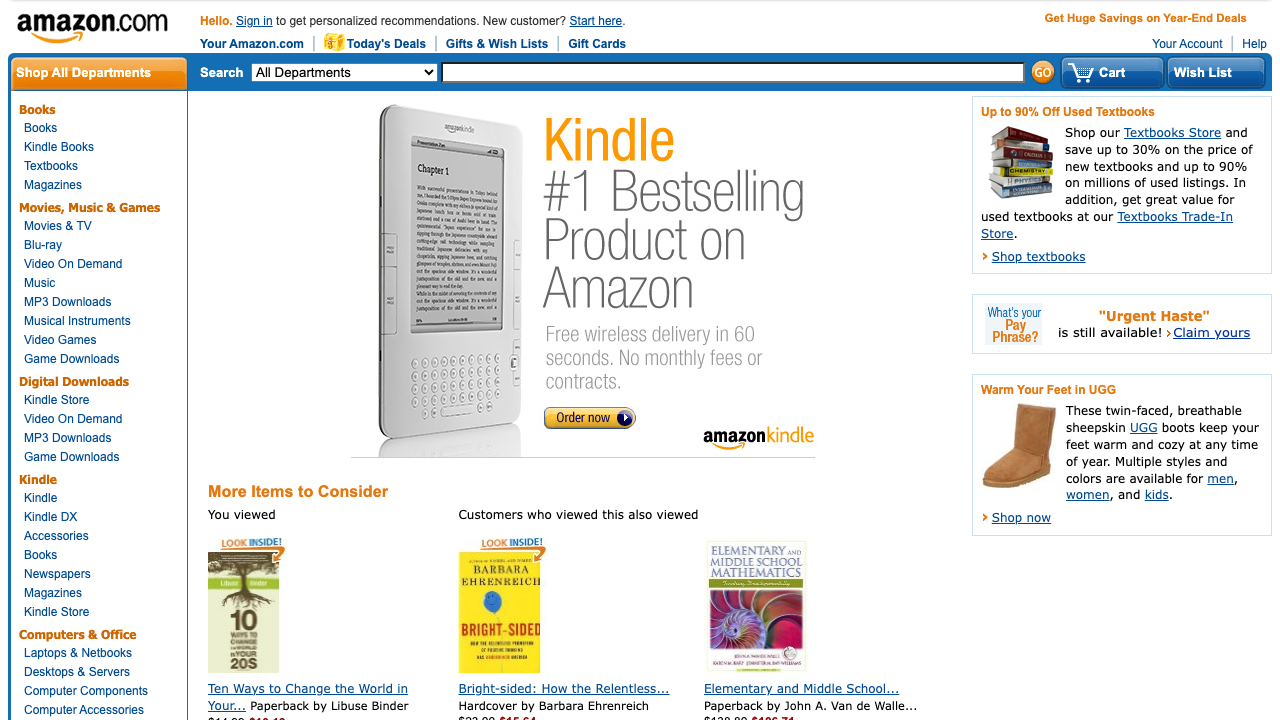
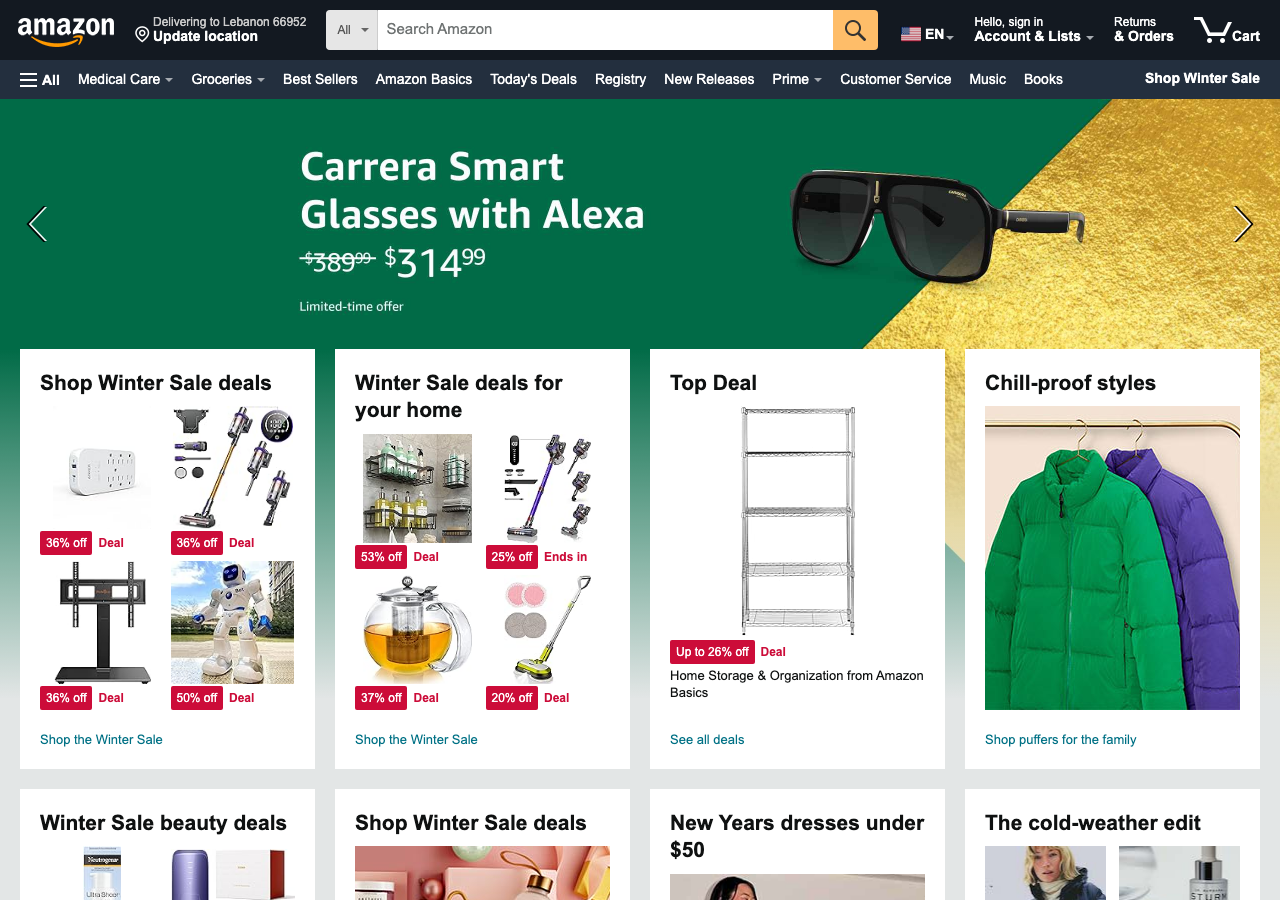
This walkthrough uses public Internet Archive snapshots of Amazon homepages for a retrospective product demo. This is a Flock-curated product walkthrough, not a customer case study, and it does not use customer data. Amazon did not use Flock for these pages, and this example is not affiliated with, sponsored by, or endorsed by Amazon.
Open the public walkthroughCurrent beta pricing
Public pricing keeps evaluation concrete: pick a run volume, understand the seat model, and decide whether the current beta shape fits.
Pricing may evolve as the product expands. Existing customer terms are honored according to the plan selected at signup.
For solo builders
$59 /mo
$47/mo with annual billing
For growing teams
$179 /mo
$143/mo with annual billing
For teams at scale
Starts at $400 /mo
4-seat minimum; additional seats at $100/seat/mo
A run is one completed synthetic user review against a URL, persona, and goal. Included runs reset each billing cycle.
View pricing detailsPrivate beta access
Join the waitlist with the preview, staging, or release workflow you want tested first. We prioritize teams with active product surfaces and concrete evidence needs.
Have an invite code?
Codes are for teams already approved for the private beta.
Need beta access?
Share the workflow, product surface, and team context that would make Flock useful now.
Join waitlistWe collect only the fields in the request form and do not use waitlist submissions for third-party marketing.